
(画面左下にMathJaxのタイプセットステータスが表示されます。)
環境によっては表示が崩れているかもしれません。その際はブラウザーを変更してみてください。
多重重点的サンプリング (Multiple Importance Sampling)
完璧な重点的サンプリングを行うことでモンテカルロ法の分散をゼロにすることができますが、CGのレンダリングのような高次元の問題ではまず不可能です。積分領域に関して部分的に優れたいくつかの確率分布からサンプルがとれる場合、多重重点的サンプリングを用いることで、それぞれを独立して使う場合よりも分散を抑えることが可能です。
1次元積分の例
モンテカルロ法の基礎説明と同じく、また簡単な1次元積分を例に説明をします。上の図のような2つのピークを持つ関数を考えます。理想は関数形状に比例したPDFに沿ってサンプルをとることですが、被積分関数が解析的に表せない場合や、そもそも明確な形状がわかっていない場合にはそのようなPDFを考えることは困難です。
ここで、部分的に優れた2つのPDF $ p_1(x) $ と $ p_2(x) $ に沿ってサンプリングができるとします。それぞれ一方だけを使った場合のモンテカルロ推定量は次のようになります。 \begin{equation*} \Abk{I} = \frac{1}{N_1} \sum_{i = 1}^{N_1} \frac{f(x_i)}{p_1(x_i)} \hspace{10mm} \Abk{I} = \frac{1}{N_2} \sum_{i = 1}^{N_2} \frac{f(x_i)}{p_2(x_i)} \end{equation*} 図を見ればわかるように、$ p_1(x) $ は左側のピーク周辺、$ p_2(x) $ は右側のピーク周辺で被積分関数と似た形状をとっているため、これらのPDFは部分的には優れています。しかし $ p_1(x) $ を使うと、低い確率で関数値の大きな箇所(右側のピーク)をサンプリングしてしまうため、モンテカルロ法における $ f(x) / p_1(x) $ の値の分散が大きくなってしまいます。$ p_2(x) $ に関しても同様です。2つのPDFからのサンプリング戦略が使えるため、分散を抑えるためにすぐに思いつく方法として推定量の平均をとることがあるでしょう。 \begin{equation*} \Abk{I} = \frac{1}{2} \Brcd{ \frac{1}{N_1} \sum_{i = 1}^{N_1} \frac{f(x_i)}{p_1(x_i)} + \frac{1}{N_2} \sum_{i = 1}^{N_2} \frac{f(x_i)}{p_2(x_i)} } \end{equation*} これによってそれぞれの苦手な部分を補い合うことができる一方、得意な部分も潰し合ってしまうため単なる平均は良い推定量にはなりません。次の節では、部分的に優れたPDFのセットをうまく組み合わせて分散を低減する多重重点的サンプリング(Multiple Importance Sampling, MIS)というテクニックについて紹介します。
マルチサンプルモデル
それぞれの戦略から1つ以上のサンプルがある場合、各サンプル毎に異なるウェイトを考えることで、以下のマルチサンプル推定量を得ます。
\begin{equation}
\Abk{I} = \sum_{i = 1}^{N} \frac{1}{n_i} \sum_{j = 1}^{n_i} w_i(x_{i, j}) \frac{f(x_{i, j})}{p_i(x_{i, j})} \label{eq:multi_sample_estimator}
\end{equation}
ここで、$ N $ がサンプリング戦略の数、$ n_i $ が戦略 $ p_i $ からのサンプル数、$ x_{i, j} $ が戦略 $ p_i $ からの $ j $ 番目のサンプルを表しています。また、各サンプルにはウェイト $ w_i(x_{i, j}) $ がかけられます。注意点としてウェイトは定数である必要がありません。
この推定量がunbiased、つまり期待値が真値に一致するためには、満たさなければならない2つの条件があります。
| $ \mathrm{(W1)} $ | $ f(x) \neq 0 $ なら必ず $ \displaystyle \sum_{i = 1}^{N} w_i(x) = 1 $ |
| $ \mathrm{(W2)} $ | $ p_i(x) = 0 $ なら必ず $ w_i(x) = 0 $ |
これらについて考える前にモンテカルロ法の基礎について思い出してみます。PDF $ p(x) $ に沿ってサンプルされた $ x $ に関する推定量への寄与は $ f(x) / p(x) $ です。この寄与を取りうる確率密度は当然 $ p(x) $ なので、サンプル $ x $ における寄与の期待値は $ f(x) $ となります。これを積分領域 $ D $ 全体について考えれば $ \int_D f(x) dx $ となるので積分がunbiasedに求まります。つまり、何が言いたいかというと、積分がunbiasedに求まるためには、あるサンプル点に対して被積分関数の値もunbiasedに求まっている必要があります。
それでは $ \mathrm{(W1)} $ について考えます。サンプル $ x $ がある戦略 $ p_a $ から生成される確率密度は $ p_a(x) $ です。推定量の値は $ w_a(x) \cdot f(x) / p_a(x) $ です。この値が起こりうる確率密度は $ p_a(x) $ なので期待値は $ w_a(x) \cdot f(x) $ です。同じサンプル $ x $ が別の戦略 $ p_b $ から生成される確率密度は $ p_b(x) $ で、期待値は $ w_b(x) \cdot f(x) $ です。マルチサンプル推定量は複数の戦略の和となっているため、あるサンプル $ x $ に関する期待値が真値 $ f(x) $ に一致するためにはウェイトの合計が $ 1 $ になる必要があることがわかると思います。
$ \mathrm{(W2)} $ について考えます。これは $ p_i(x) = 0 $、つまり $ p_i $ からは起こり得ないサンプル $ x $ に関してウェイトが設定されてしまうと、他の戦略のウェイトが $ \mathrm{(W1)} $ に従って小さくなることを意味します。これでは各サンプル点に関して関数値をunbiasedに求められません。そのため $ p_i $ から起こりえないサンプルに対してウェイト $ w_i $ はゼロとなっている必要があります。
これらより言えることがあります。それは、それぞれの戦略が積分範囲全てをサンプリングできる能力を持つ必要は無いということです。領域中の各点に関して少なくとも1つの戦略がサンプリングできれば問題ありません。
バランスヒューリスティック(Balance Heuristic)
$ \mathrm{(W1)} $ と $ \mathrm{(W2)} $ を満たすマルチサンプルモデルにおけるサンプリング戦略の結合方法は色々とありますが、分散を最小化することにおいて、ひとつの良い方法として以下のウェイトの計算方法があります。 \begin{equation} w_i(x) = \frac{n_i p_i(x)}{\sum_{k = 1}^{N} n_k p_k(x)} \label{eq:balance_heuristic} \end{equation} 実にシンプルです。各戦略のサンプル数 $ n_i $ を確率密度の一部として考える($ p(x) $ から $ n $ サンプルとる場合 $ p'(x) = np(x) $ と考えられる。)のなら全ての確率密度の和において自身が占める割合がウェイトとして与えられていることに相当します。このウェイトの計算方法をバランスヒューリスティック(balance heuristic)と呼び、その特徴として他のあらゆる結合方法よりも大体の場合優れていることがあります。証明もされていますが、ここでは省略します。注意点として、分母分子ともに各PDFの入力は同じサンプル $ x $ です。このウェイトを計算するとき $ x $ は $ p_i $ からサンプリングされていますが、$ x $ が他のサンプリング戦略からとられた場合の確率密度を計算することでウェイトが計算できます。
バランスヒューリスティックの簡単な解釈
バランスヒューリスティックの式 $ \eqref{eq:balance_heuristic} $ を式 $ \eqref{eq:multi_sample_estimator} $ に代入すると次の式となります。 \begin{eqnarray*} \Abk{I} &=& \sum_{i = 1}^{N} \frac{1}{n_i} \sum_{j = 1}^{n_i} \frac{n_i p_i(x_{i, j})}{\sum_{k = 1}^{N} n_k p_k(x_{i, j})} \frac{f(x_{i, j})}{p_i(x_{i, j})} \\ &=& \sum_{i = 1}^{N} \sum_{j = 1}^{n_i} \frac{f(x_{i, j})}{\sum_{k = 1}^{N} n_k p_k(x_{i, j})} \\ &=& \frac{1}{M} \sum_{i = 1}^{N} \sum_{j = 1}^{n_i} \frac{f(x_{i, j})}{\sum_{k = 1}^{N} c_k p_k(x_{i, j})} \end{eqnarray*} ここで、$ M = \sum_{i = 1}^{N} n_i $ で各戦略のサンプル数の合計、$ c_k = n_k \;/\; M $ は全サンプル数 $ M $ のうち、戦略 $ p_k $ からのサンプル数の割合です。よく見ると、上の式は基本的なモンテカルロ推定量とほぼ同じ形式になっていることがわかります。分母を $ \hat{p}(x_{i, j}) = \sum_{k = 1}^{N} c_k p_k(x_{i, j}) $ とおけばもっとわかりやすいと思います。つまり、バランスヒューリスティックでは取りうる各戦略の加重平均PDF($ n_k = 1 $ ならただの平均)からのサンプリングを行っていることと等しくなります。
パワーヒューリスティック(Power Heuristic)
バランスヒューリスティックは大体の場合で最適な結合方法ですが、一部では他の結合方法のほうが優れた結果を持ちます。例えば2つのサンプリング戦略 $ p_1 $ と $ p_2 $ を考え、$ p_1 $ が被積分関数に対して完全に比例している場合、いっそMISは使わず、$ p_1 $ からだけサンプリングするほうが好ましくなります。しかし、被積分関数がどのようなものか明確にわからない状況では、それが最適かどうかも判断できません。そのため結局MISを使う方が無難となりますが、上記問題を軽減するためにパワーヒューリスティック(power heuristic)という方法があり、ウェイトは以下のように計算されます。 \begin{equation} w_i(x) = \frac{\Brca{n_i p_i(x)}^\beta}{\sum_{k = 1}^{N} \Brca{n_k p_k(x)}^\beta} \label{eq:power_heuristic} \end{equation} ここで $ \beta $ はウェイト関数の鋭さを調整するパラメーターで、$ \beta = 1 $ の場合にバランスヒューリスティックとなることは一目瞭然です。$ \beta $ の値が大きいほど、大きな値をもつPDFのウェイトが支配的になります。$ \beta = 2 $ が程よい値になるそうです。
光輸送問題への応用
MISの応用先は非常に広く、レンダリングの計算でも様々な場面で使うことができます。ここでは光沢面に対する直接照明を例にMISの応用を紹介します。
視点を $ \vz $、着目している点を $ \vx $、光源上の点を $ \vy $ とすると、直接照明による反射光 $ L_r $ は次の積分で表されます。
\begin{equation*}
L_r(\vx \RAR \vz) = \int_{\mathcal{M}} f_s(\vy \RAR \vx \RAR \vz) L_e(\vy \RAR \vx) G(\vy \LRAR \vx) \d A(\vy)
\end{equation*}
ほとんどレンダリング方程式の右辺2項目と同じですが、ここでは直接照明に限定しているため積分内の輝度項が $ L_e $ となっています。さて、この積分のサンプリング方法には2種類の戦略が考えられます。1つ目はBSDFに沿った入射方向のサンプリングを行い、光源にヒットした場合に寄与を蓄積する方法、2つ目は光源上の位置 $ \vy $ を選んで $ \vx $ と接続する方法(Next Event Estimation, NEE)です。図で表すと次のようになります。
BSDFのサンプリングは、サンプルした入射方向に光源が無かった場合寄与がとれません。そのためBSDFが拡散面のようにピークを持たない場合や、光源が小さい、遠い場合には分散が大きくなってしまいます。光源面のサンプリングは、光源が大きくBSDFの光沢度が高い場合に、サンプルした光源上の位置がなかなか大きな寄与を持たず分散が大きくなってしまいます。以下にそれぞれの戦略によるレンダリング画像を示します。

|

|
| BSDFのサンプリング | 光源面のサンプリング |
このシーンでは4枚の光沢を持った板が並べられており、上にいくほど光沢度が高くなっています。それらを色とサイズが異なる4つの球光源が照らしています。ここでは光沢のある板にのみ着目してください(背景等は別処理で結果を揃えています)。上で述べた通り、左下に着目すると光沢度が低いBSDFかつ光源が小さいため、BSDFサンプリングでは分散が非常に大きくなっています。逆に右上に着目すると、光沢度の高いBSDFかつ光源が大きいため、光源面サンプリングでは分散が大きくなっています。
これら2つの戦略をMISでうまく組み合わせることを考えます。BSDFサンプリングにおける入射方向に関する確率密度は $ p_{\sigma, BSDF}(\vx \RAR \vy) $、光源面サンプリングにおける位置に関する確率密度は $ p_{A, light}(\vy) $ です。いずれも $ \vy $ のサンプリングに関する確率密度を表しており、これらを使ってウェイトを計算するのですが、非常に重要なことがあります。それは、これら2つの確率密度が異なる測度に関して表されているということです。簡単に言うと単位が違います。前者の単位は $ [\mathrm{sr}^{-1}] $、後者は $ [\mathrm{m}^{-2}] $ です。パワーヒューリスティックなどでは確率密度の加算を行いますが、単位が異なるものを足し合わせるのは御法度です。そのため、測度を揃える必要があります。どちらに揃えてもいいのですが、ここでは後者に合わせることにしましょう。
他の記事でも何度か出ましたが、微小立体角と微小面積の間には次の関係が成り立ちます。
\begin{equation*}
\d\vomega(\vx \RAR \vy) = \frac{\absb{\vomega_{\vx \vy} \cdot \vec{n}_\vy}}{\norm{\vy - \vx}^2} \d A(\vy)
\end{equation*}
それぞれの微少量と確率密度の間には逆数の関係があるので、2つの確率密度の変換式は次のように求められます。
\begin{equation*}
p_A(\vy) = \frac{\absb{\vomega_{\vx \vy} \cdot \vec{n}_\vy}}{\norm{\vy - \vx}^2} p_\sigma(\vx \RAR \vy)
\end{equation*}
この変換式より $ p_{A, BSDF}(\vy) $ を求めることができ、測度を揃えることができました。パワーヒューリスティックを使って2つの戦略を組み合わせることによって以下のようなレンダリング結果が得られます。

|
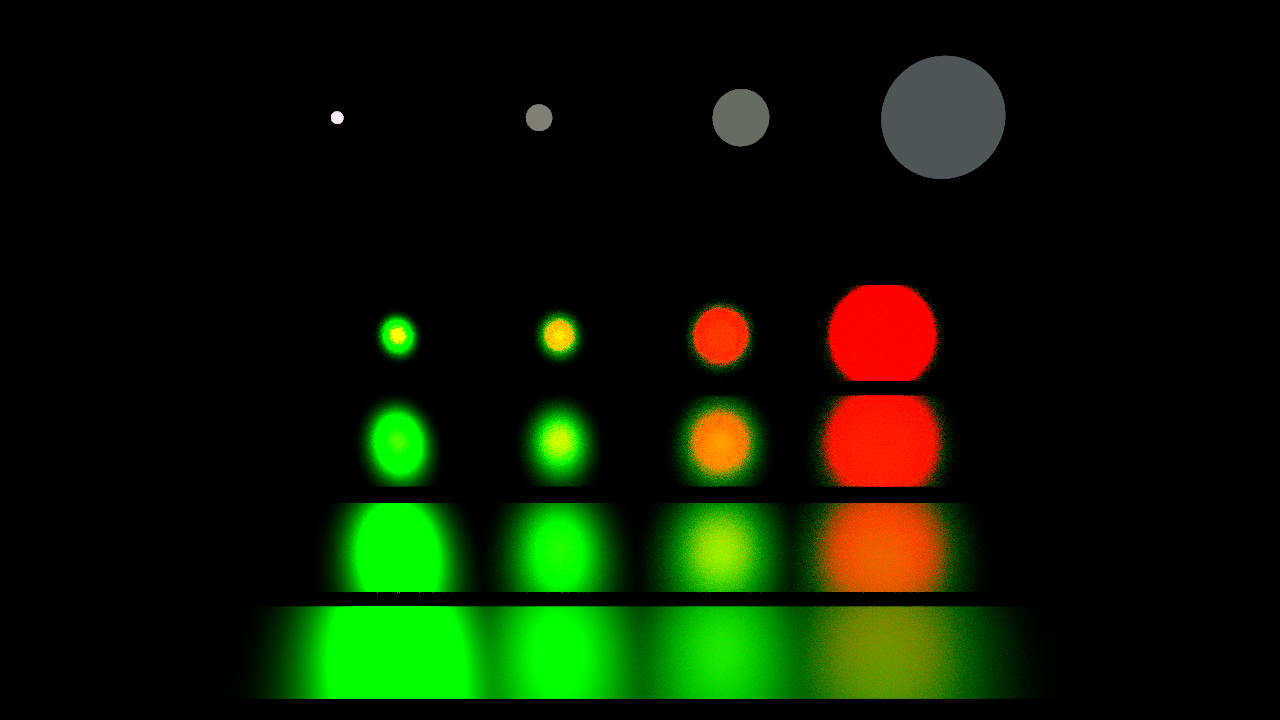
|
| パワーヒューリスティック( $ \beta = 2 $ ) | MISウェイト(× 輝度) |
見事MISによって分散が劇的に低減できていることがわかります。計算時間も多少伸びますが、一方の戦略のみで同じ時間をかけてもこのような収束は見れません。右にMISウェイトの可視化結果を載せています。赤色がBSDFサンプリング、緑色が光源面サンプリングを表しています。それぞれが得意な領域で適切なウェイトが与えられていることが見てとれます。
理想スペキュラー面の取り扱い
理想スペキュラー面においてBSDFのサンプリング(というか一意な方向選択)を行う場合、そのPDFはデルタ関数で表されます。したがって理想スペキュラー面をサンプルして光源に到達した場合の確率密度は無限大の大きさを持ちます。一方で光源面内を直接サンプルして得た位置・方向に関して理想スペキュラー面のBSDFの確率密度はゼロとして評価されます。したがってMISウェイト $ \eqref{eq:balance_heuristic} $ や $ \eqref{eq:power_heuristic} $ は理想スペキュラー面をサンプルして光源にヒットした場合は1、光源面を明示的にサンプルした場合は0になります。
1サンプルモデル
ここまで紹介してきたマルチサンプルモデルでは、全てのサンプリング戦略から1つ以上サンプルがとれる場合を考えていました。1サンプルモデルでは、1つのサンプリング戦略を確率的に選択し、そこから1つだけサンプルをとります。1サンプル推定量は次のように表されます。 \begin{equation*} \Abk{I} = w_i(x_i) \frac{f(x_i)}{c_i p_i(x_i)} \end{equation*} ここで $ c_i $ は戦略 $ p_i $ が選ばれる確率を表しています。1サンプルモデルの場合も大体良いと考えられるウェイトの計算方法はバランスヒューリスティックとなります。つまりウェイト $ w_i $ は次の式で表されます。 \begin{equation*} w_i(x) = \frac{c_i p_i(x)}{\sum_{k = 1}^{N} c_k p_k(x)} \end{equation*} この1サンプルモデルは、レンダリングにおいて複数のBSDFからなる合成BSDFから反射方向をサンプリングする際などに用いられます。
参考文献
- [Veach1998] Eric Veach, Leonidas J. Guibas - "ROBUST MONTE CARLO METHODS FOR LIGHT TRANSPORT SIMULATION", 1998